在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 近 实时搜索: 文档的变化并不是立即对搜索可见,
但会在一秒之内变为可见。
这些行为可能会对新用户造成困惑: 他们索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用 refresh API 执行一次手动刷新:
#刷新所有索引。POST /refresh#刷新my_logs索引。POST /my_logs/_refresh
尽管刷新是比提交轻量很多的操作,它还是会有性能开销。 当写测试的时候, 手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。
相反,你的应用需要意识到 Elasticsearch 的近实时的性质,并接受它的不足。
并不是所有的情况都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件, 你可能想优化索引速度而不是近实时搜索, 可以通过设置 refresh_interval , 降低每个索引的刷新频率:
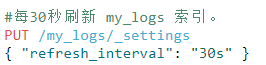
refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来:
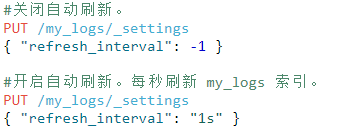
refresh_interval 需要一个 持续时间 值, 例如 1s (1 秒) 或 2m (2 分钟)。 一个绝对值 1 表示的是 1毫秒 --无疑会使你的集群陷入瘫痪。
例子:
#创建索引PUT /my_logs/#关闭自动刷新。PUT /my_logs/_settings{ "refresh_interval": -1 }#刷新所有索引。POST /refresh#手动刷新my_logs索引。POST /my_logs/_refresh#索引数据POST /my_logs/mytype{ "title":"hello1"}#开启自动刷新。PUT /my_logs/_settings{ "refresh_interval": "1s" }#查询数据GET /my_logs/mytype/_search